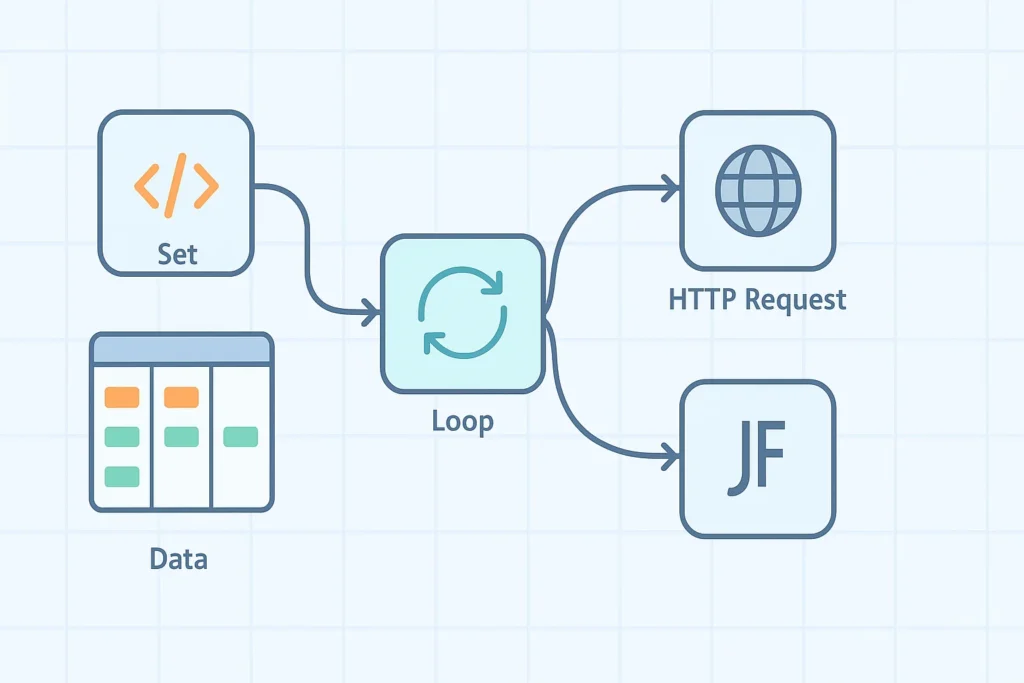
當你從單筆資料的自動化,開始邁向需要處理成千上百筆資料的複雜流程時,一個核心的程式設計概念便會浮上檯面:「迴圈 (Loop)」。你可能會想,如何在 n8n 中實現一個迴圈,讓工作流能夠聰明地一筆一筆處理從 Google Sheets、資料庫或 API 來的海量資料?
如果你直覺地在 n8n 節點庫中搜尋 “Loop” 或 “For Each”,你會發現一個驚人的事實:n8n 並沒有一個專門叫做「迴圈」的節點。這並非 n8n 的功能缺失,恰恰相反,這是它設計哲學中最高明的部分之一。n8n 將迴圈的概念內化到了它的核心運作機制中,提供了兩種強大的模式來處理多筆資料:一種是幾乎讓你感受不到存在的「自動化迴圈」,另一種則是讓你擁有精準控制權的「手動批次迴圈」。
這篇文章將是你最完整的 n8n 迴圈實戰指南。我們將徹底解析這兩種迴圈模式的運作原理與天壤之別,並透過實戰情境對決,教你何時該用哪一種。最後,我們還會深入探討處理「巢狀資料」等進階迴圈技巧,讓你真正成為 n8n 多筆資料處理的高手。
模式一:n8n 的隱藏預設技 — 看不見的「自動化迴圈」
n8n 之所以讓許多使用者感到驚艷,就在於其極度直觀的「隱性迴圈」機制。這個概念是所有 n8n 使用者都必須理解的基石。
什麼是自動化迴圈?
簡單來說,n8n 中絕大多數的執行節點(Action Nodes),預設都會自動對從上游傳來的所有資料 (Items) 逐一執行一次。你不需要任何額外的設定,這個迴圈就會自然發生。
把它想像成一個自動化的工廠作業員:
- 上游傳來 50 個箱子 (50 個 Items)。
- 作業員的任務是為每個箱子貼上標籤 (例如
Set節點的功能)。 - 作業員不會問你「我是不是要做 50 次?」,他會二話不說,拿起第一個箱子、貼標籤、送走;再拿起第二個、貼標籤、送走……直到全部 50 個箱子都處理完畢。
這就是 n8n 的預設行為。一個 Google Sheets 節點讀取了 50 列資料,它就會輸出 50 個 Items。下游的 Send Email 節點接收到這 50 個 Items 後,就會自動執行 50 次,發送 50 封客製化的 Email。整個過程行雲流水,你看不到任何傳統迴圈的語法,但迴圈的實質效果卻已經完美達成。
自動化迴圈的優勢
- 極致簡潔: 你的工作流畫布可以保持乾淨的線性結構,大幅提升可讀性。
- 直觀易懂: 你只需要專注在「單一筆資料」要如何被處理,n8n 會自動幫你將這個邏輯應用到所有資料上。
模式二:需要精準控制?Split In Batches 節點登場
自動化迴圈雖然方便,但在某些進階情境下,我們需要奪回對迴圈的精準控制權。這時候,Split In Batches 節點就是你的手動排檔桿。這個節點的核心功能是將大量的 Items 切割成固定大小的「批次 (Batch)」,它主要解決以下兩大問題:
應用一:批次處理以應對 API 速率限制
這是 Split In Batches 最重要的用途。幾乎所有外部 API 服務都有速率限制(Rate Limit),例如「每分鐘最多請求 60 次」。如果你有 300 筆資料要透過 API 更新,n8n 的自動迴圈會在幾秒內就發出 300 次請求,立刻就會超過限制而被封鎖。
解決方案:
- 在資料來源與
HTTP Request節點之間,插入一個Split In Batches節點。 - 將
Batch Size(批次大小) 設定為60。 - 在
Split In Batches和HTTP Request之間,再插入一個Wait節點,設定等待60秒。
如此一來,流程會先處理第一批 60 筆資料,然後暫停一分鐘,再處理下一批,完美地將請求頻率控制在 API 的安全範圍內。
應用二:實現「逐一執行」的 For-Each 迴圈
有時候,你希望確保每一筆資料都嚴格地按照順序、一筆處理完才處理下一筆。這時,你只需要將 Batch Size 設定為 1。
這個設定會將每一筆 Item 都當作一個獨立的批次,強制下游的節點「一次只做一件事」。這在處理有前後依賴性的任務時(例如,必須先成功建立用戶 A,才能用用戶 A 的 ID 去建立訂單 A)非常關鍵。
實戰情境對決:自動迴圈 vs. Split In Batches
讓我們透過兩個情境,來看看這兩種模式的實際應用與選擇時機。
| 情境 | 任務目標 | 最佳選擇 | 原因分析 |
| 行銷郵件群發 | 從 CRM 讀取 1000 位 VIP 客戶,為每人寄送一封客製化的生日祝福信。 | 自動化迴圈 (不需額外節點) | 寄送郵件的任務之間沒有相互依賴,可以平行高速處理。n8n 的自動迴圈機制能以最高效率完成任務。 |
| 電商庫存同步 | 從 ERP 讀取 500 項商品庫存異動,透過 API 更新到 Shopify 官網。Shopify API 限制每秒 2 次請求。 | Split In Batches | 這是典型的速率限制問題。必須使用 Split In Batches (Batch Size: 2) 搭配 Wait (1 秒) 來精準控制請求節奏,確保流程穩定不失敗。 |
判斷法則: 當你的任務可以「平行處理」且沒有外部限制時,請信賴 n8n 的自動迴圈。當任務需要「控制節奏」或「嚴格排序」時,就使用 Split In Batches。
進階迴圈技巧:處理「巢狀資料」中的迴圈
一個常見的進階挑戰是:單一筆訂單資料 (一個 Item) 中,可能包含了多個購買品項的陣列 (Nested Array)。如果你想對「每一個購買品項」都執行一次動作(例如,逐一查詢各品項的庫存),該怎麼辦?
這時,n8n 的自動迴圈無法直接處理到這麼深的層級。你需要一個能將巢狀陣列「攤平」的工具。
- 目標: 一筆訂單資料
{"order_id": 101, "line_items": [{"prod_id": "A"}, {"prod_id": "B"}]},要針對line_items裡的 A 和 B 商品,分別執行庫存查詢。 - 解決方案: 使用
Split Into Sub-items節點。- 在 Field to Split Out 欄位,指定你要攤平的陣列欄位名稱,在此例中為
line_items。 - 這個節點的輸出,會將原本的 1 筆 Item,變成 2 筆新的 Items。
- Item 1:
{"order_id": 101, "prod_id": "A"} - Item 2:
{"order_id": 101, "prod_id": "B"}
- Item 1:
- 如此一來,下游的庫存查詢節點,就能利用 n8n 的自動迴圈,分別處理 A 和 B 兩筆資料了!
- 在 Field to Split Out 欄位,指定你要攤平的陣列欄位名稱,在此例中為
打破迴圈:如何將多筆資料彙總為單一結果?
學會了如何執行迴圈,也要學會如何「跳出迴圈」。有時候,我們的目的不是為每一筆資料都執行一次動作,而是要將所有資料的結果「彙總」成一個。
- 情境: 你讀取了當天所有的 100 筆訂單資料,但你只想發送「一封」Slack 通知給老闆,告訴他「今日總營業額」。
- 解決方案: 使用
Item Lists節點來終止迴圈。- 在資料來源之後,接上
Item Lists節點。 - Operation: 選擇
Summarize(彙總)。 - Field to Aggregate: 選擇你要計算的欄位,例如
order_amount。 - Aggregation: 選擇
Sum(加總)。
- 在資料來源之後,接上
這個節點會「吃掉」所有傳入的 100 個 Items,然後只輸出一個 Item,裡面包含一個 sum 欄位。這樣,下游的 Slack 節點因為只收到一個 Item,就只會執行一次,完美達成你的彙總報告需求。

結語
n8n 在迴圈處理的設計上,採取了一種極度優雅且高效的哲學。它移除了傳統程式設計中繁瑣的迴圈語法,讓使用者能夠專注於核心的業務邏輯。
讓我們再次總結 n8n 的迴圈心法:
- 相信自動化: 對於大多數平行任務,n8n 的「自動迴圈」是你最可靠的預設選項。
- 精準控制用
Split In Batches: 當需要控制速率或確保執行順序時,用它來實現「批次處理」或「逐一執行」。 - 深入巢狀用
Split Into Sub-items: 處理 Item 內部陣列的迴圈問題。 - 彙總結果用
Item Lists: 當你需要從多筆資料計算出單一結果時,用它來打破迴圈。
你之所以找不到一個叫做 “Loop” 的節點,正是因為迴圈的能力已經無所不在地融入到 n8n 的每一個角落。理解並善用這兩種模式,你就能充滿信心地處理任何規模的資料,打造出更強大、更穩健的自動化工作流。